


How was Google Cloud Summit in Prague?
And what was interesting for SEO?


12th of June was in Prague a big conference organized by Google. It wasn't about search - the main topic was Google Cloud Platform (GCP) And because GCP is still something useful for SEO we were there.
At that conference, there were a lot of topics and lots of nice food from Google's budget. Still, for us, the main goal was to get more information about Vertex AI which is a generative AI part of GCP (something like playground OpenAI), and also some more details about BigQuery which is great for analytical use.
An article full of the best of the conference day is there! 🚀
Keynote
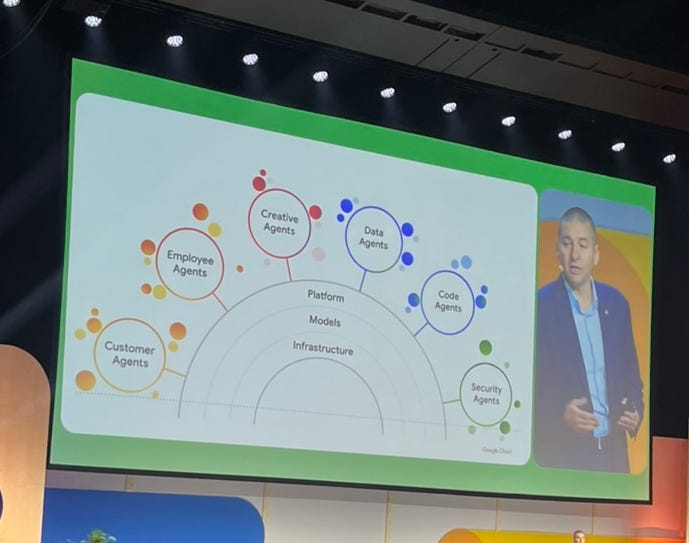
The Google Cloud Summit 2024 starts with a presentation about AI agents. Google Cloud CEO 🔗 Thomas Kurian introduced six types of AI agents, which are designed to assist with specific tasks across various domains:
Customer Agents
These agents understand customer needs and make recommendations across channels, acting like sales or service representatives.
Vertex AI Agent Builder
Employee Agents
These help employees by automating repetitive tasks, providing information, and enhancing productivity and collaboration.
Vertex AI, Gemini Models integrated into Google Workspace.
Creative Agents
These agents assist in creative processes, enabling users to create designs, artworks, and marketing materials efficiently.
Imagen 2.0 on Vertex AI, Google Vids
Data Agents
Acting as knowledgeable analysts, these agents can answer questions, synthesize research, and identify new queries.
BigQuery integrated with Vertex AI Gemini Models, Gemini model in Looker.
Code Agents
These support developers in building and maintaining applications and systems.
Gemini 1.5 Pro for code assist
Security Agents
These agents aid in automating monitoring tasks and protecting data to improve and manage security operations.
Gemini in Threat Intelligence, Security Command Center
🔗 The video from the keynote and the big 🔗 Google Cloud summary from Google.
Gemini models
I can't count how much I've listened to Gemini at this conference. It was my main goal to get more information about those models. They showed them in various places that aren't usual like in BigQuery or Looker and I'm “optimistic” about the future of their models.
Now I have an unpopular opinion but I see that Gemini integrated into the Google Cloud Platform could be strong for business solutions and when Google will have better models then it should get more market share faster than Microsoft? But maybe it is the same in Azure and OpenAI but I can't see it because I don't have anything on Azure now.
For me I have one big note which was “try Gemini with its 1,5M token window” and that's my task when I get access to that context window. I should imagine pasting all of my code of small tools and trying to extend my solutions with it…
… also it should be great for a larger analysis of one specific topic-based internet. So it's time to prepare data 💪because it is not allowed to search by Google - get data and use them. Is there something like grounding where you should use your vector index or Google Index but it does not directly search as I understand it? But I should imagine that when they allow that this should be a great way how to measure SGE maybe? 🤔
Everything about their models you should find in the Vertex AI subpart of GCP and also in the “model garden” are other LLMs that are available on the market (except OpenAI) this is new and for me means that I should use one API to have interaction with more models if I need them (for benchmarking it should be useful).
Also, there is a big library of tasks that we should try with their models. So this is something to try and go deeper. Also, remember it isn't about someone who said that is bad then I not use it. Each prompt that you have / solution should perform better/worse on different models so it's needed to test it! 🧪
Machine learning-based BigQuery
MLOPS seems interesting and we were in a workshop where they showed how to easily integrate machine learning models directly in BigQuery it was like in several “small steps” they were showing it on a “fraud detection” showcase…
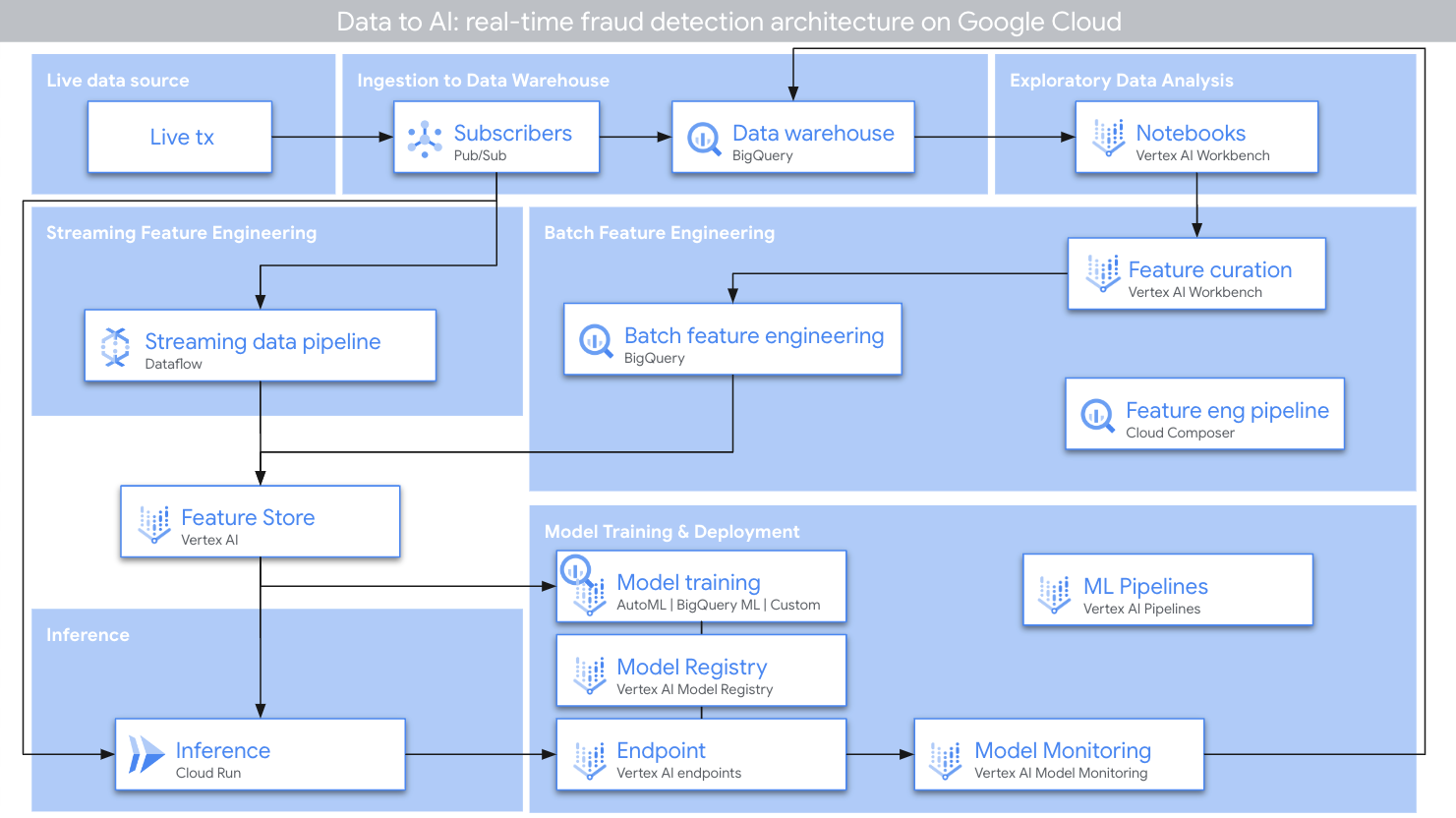
… so it won't be about SEO directly but the principles should be useful. Maybe more interesting are these use-cases for GA4 data and some user predictions which should provide us feedback if we target and acquire great users with “value” and we should get feedback directly when we start any marketing activities.
Or if we look at SEO I imagine that should be a great “exercise” to build based signals and annotation own relevance model which should “compare” pages that come in SERP - but maybe this will need much more work around like scraping data and values - but if I had it, it would work.
On the other hand, what should work should be predictions based on past data. If we have great tracking of our SEO campaigns then we should make a model that should predict based on various signals how much we should “jump” with our strategy for specific clients - but there also may depend a lot on the client so is hard to predict correctly - so at the end of the day it won't be so smooth.
But these cases will work. I think that we should predict if a specific domain/page will deliver value for our link portfolio if we get links from them or we should get inspired by 🔗 Dejan SEO which tried to predict the CTR of snippets - like when you have data then you should make this “fun” stuff there.
Practically it was a workshop where they showed us how it works. Everything is basically about declaring right “signals” that need to be calculated and annotations that show what's bad. Everything is machine learning so you have to prepare your data and in the end, it isn't as “clever” as large language models but seems like creating these models should be simple. 🔗 How to run everything you should find on Github - look at it there!
Rohlík & Data
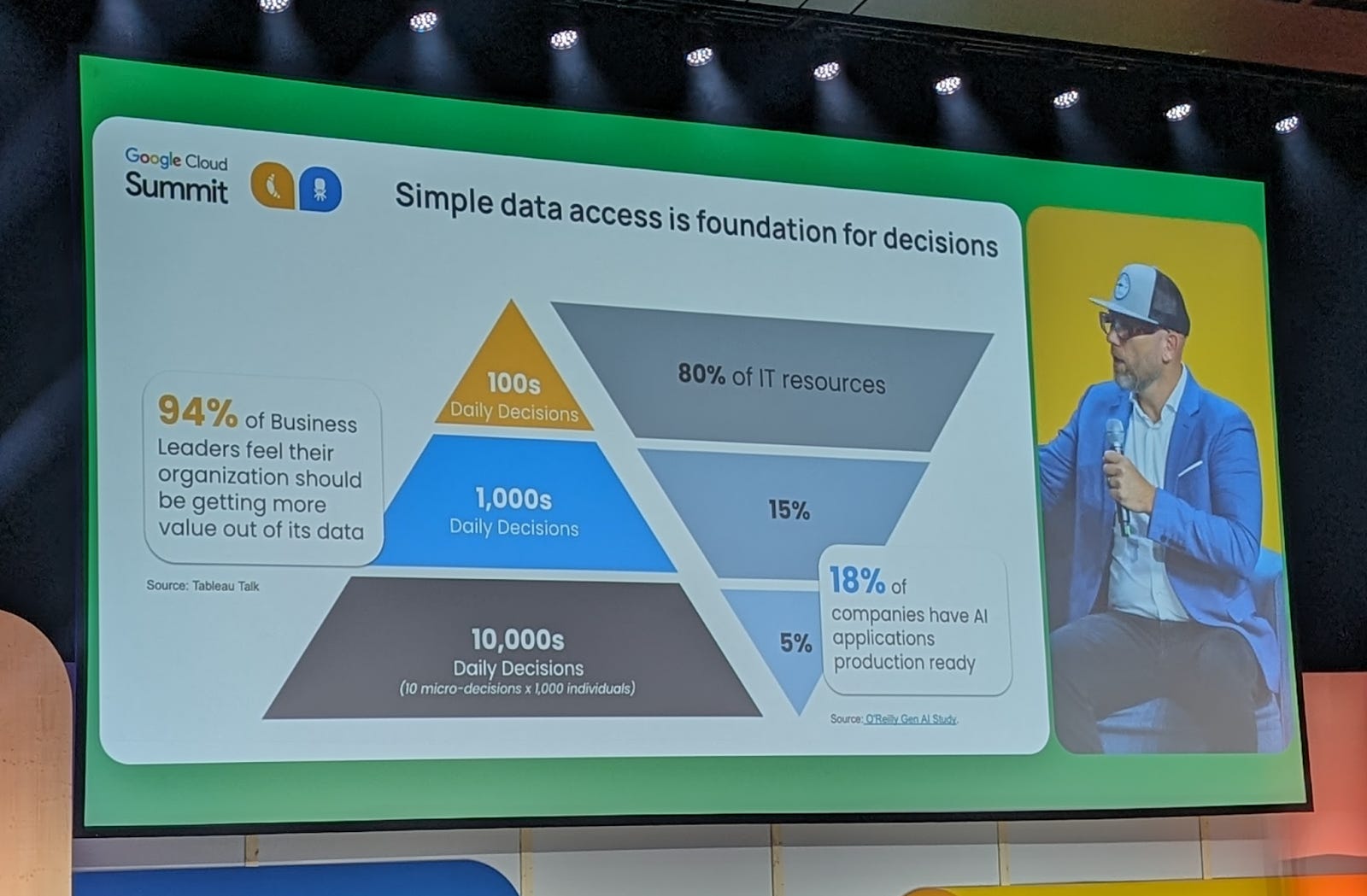
This wasn't too interesting because we know that Tomáš Čupr is building “data-oriented” companies in which he allows and supports employees to get data and make better decisions on them. After all, they also make everyday decisions that should move the company forward.
He says that it's important to provide data from your systems to all workers which will be “standardized” or “premaded-to-be-right” and after that, they should make decisions based on the data that they see. I think that he mentioned that everybody in the company knows which type of decisions should make on data → how responsible they are and where to go if you need to “approve” something bigger overall it leads to involving more people in the decision-making process - or more people can be proactive and that's good.
They also talked about Keboola that they use which is a big help for them because it helps integrate data from various sources. And for bigger companies that have a lot of components/sources to keep an eye on it seems that this is a great way to be up-to-date.
And what was a nice quote at the end of this session? “Even a bad plan is better than no plan.” So try what is possible and play with your data :)
Below is the paid part of the article where we will discuss more interesting things that we found on Google Cloud Summit in Prague. We will look more deeply at Vertex AI & RAG implementation, we will look at Vertex AI & Applications that are pre-made and ready to use…
… and we will also look at data deeper because there is something that we call “talk to data”. It should completely change how we and our employees work with data and as the last part, we will look at Customer Data Platforms.